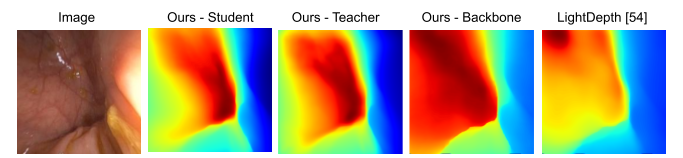
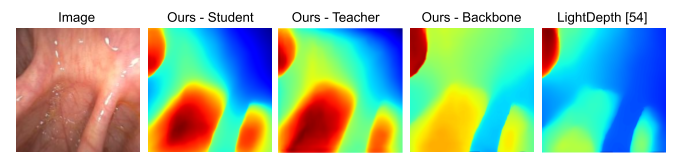
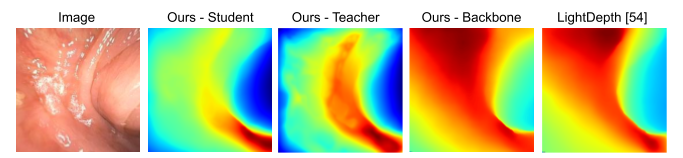
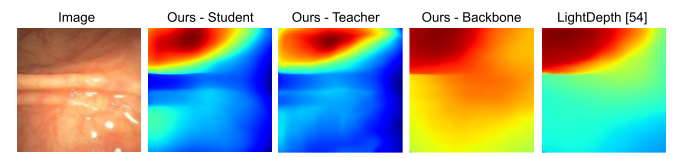
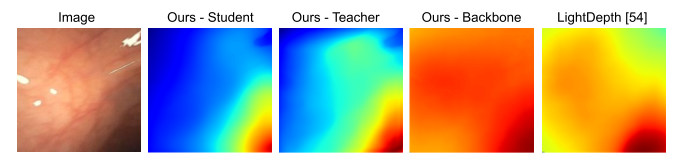
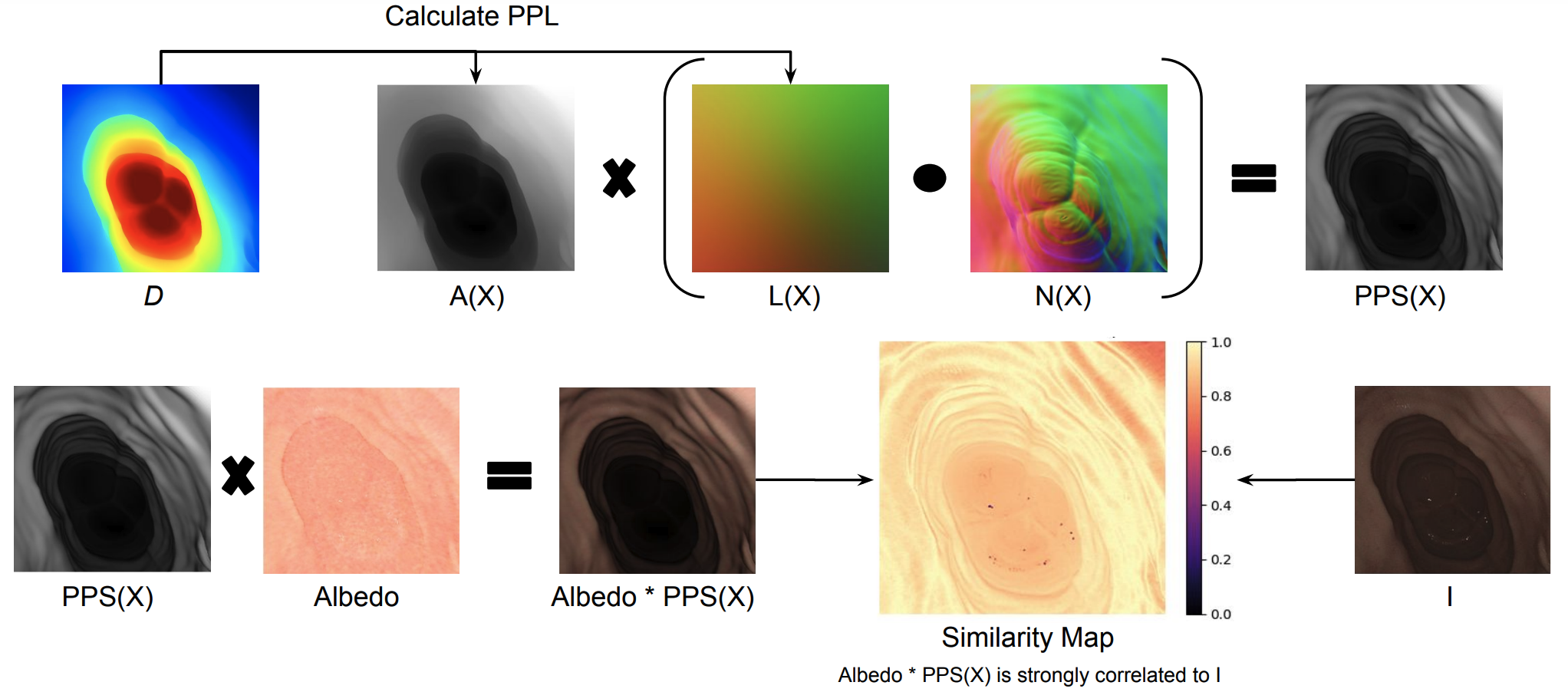
Using depths and surface normals, we compute our proposed PPS representation. Our idea relies on the fact that the PPS is strongly correlated with the image intensity field except in regions of strong specularity and it ignores inter-reflections by only modeling direct, in-view illumination from the surface to the camera. We also observe that the usage of PPS is uniform and dependable across entire datasets such as C3VD. As a result, we can utilize PPS in both supervised and self-supervised loss function variants.
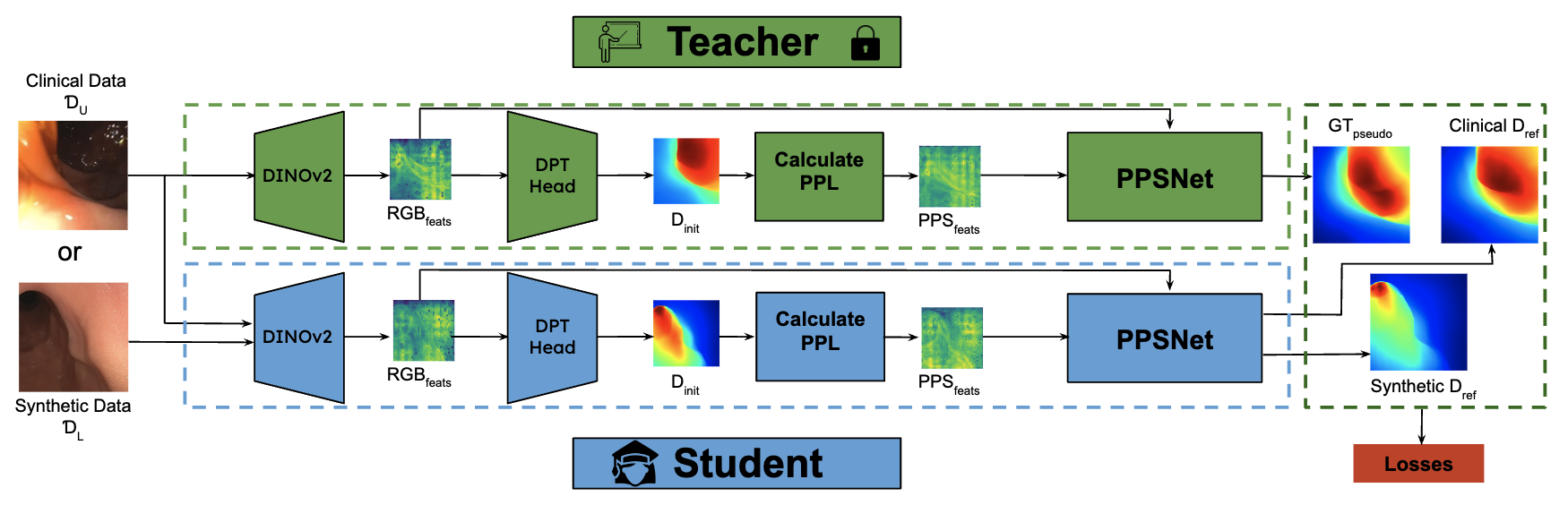
Additionally, our approach involves making an initial depth prediction and then refining that depth prediction with the help of both RGB features and PPS features. A full forward pass of our approach is included in the below algorithm table.

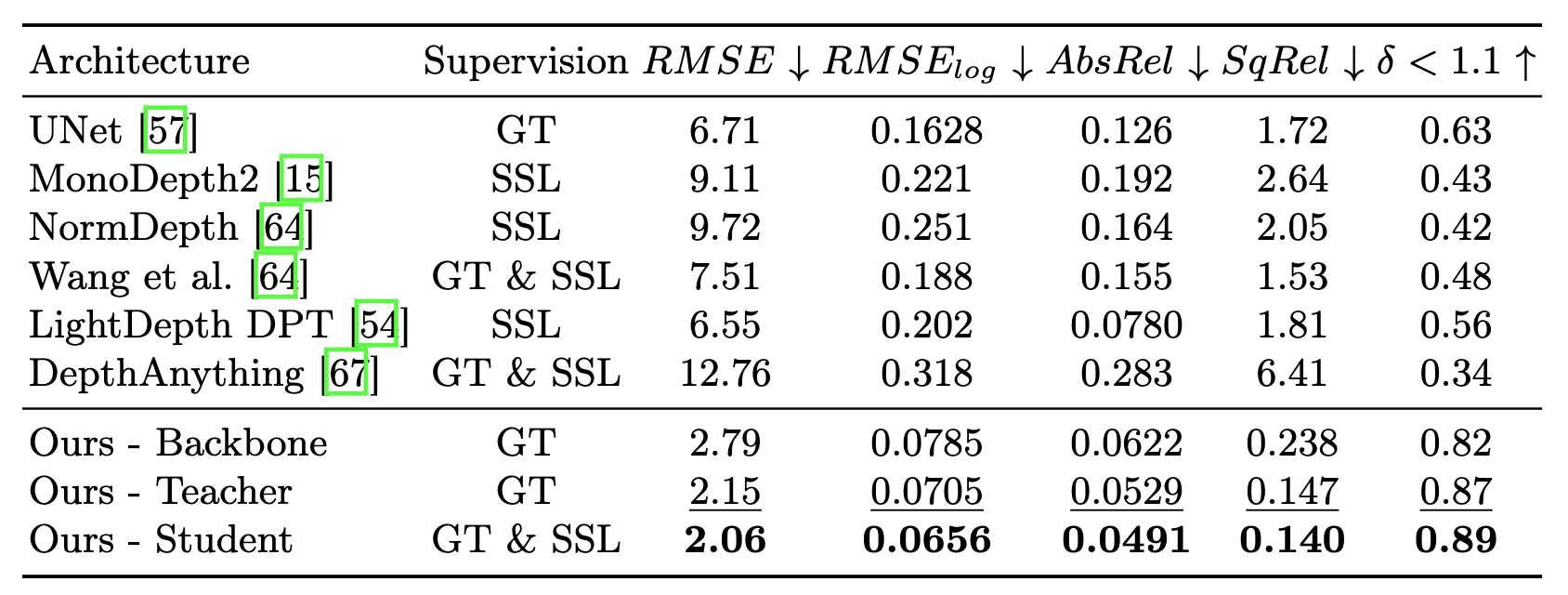
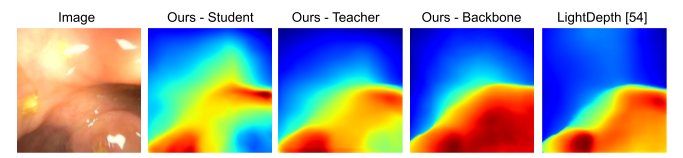
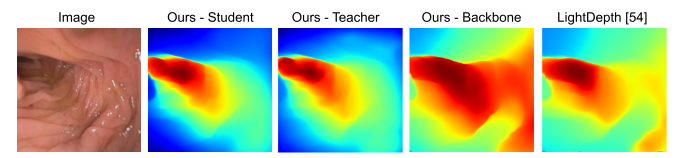
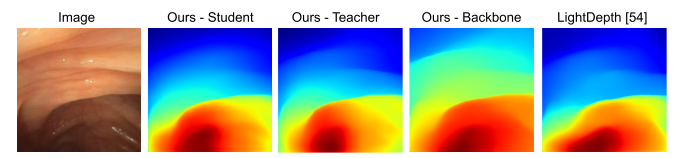
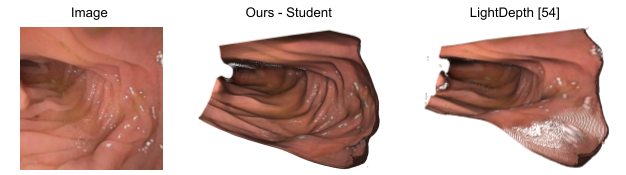
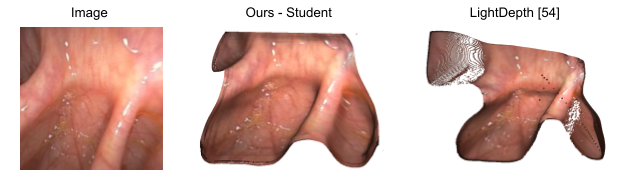
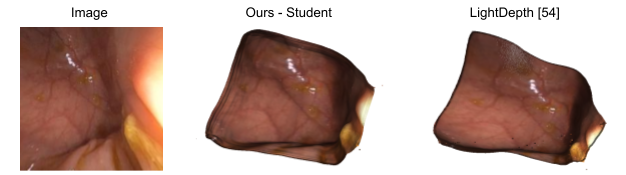
Finally, in order to leverage both synthetic, phantom colonoscopy data and more challenging, real-world clinical data as a part of our training protocol, our approach involves training a student model on both synthetic data (e.g., C3VD) and clinical data with the guidance of a teacher model trained only on synthetic data.
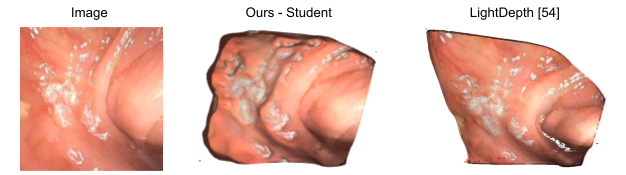
In addition to our code release which currently includes our pre-trained models and a preprocessed version of our C3VD test split, we also release mesh examples shown in the paper and our clinical data splits. The clinical dataset itself, which includes oblique and en face views, will be fully released in the near future. Please refer to our full paper for more details, including our ablations.
@article{paruchuri2024leveraging,
title={Leveraging Near-Field Lighting for Monocular Depth Estimation from Endoscopy Videos},
author={Paruchuri, Akshay and Ehrenstein, Samuel and Wang, Shuxian and Fried, Inbar and Pizer, Stephen M and Niethammer, Marc and Sengupta, Roni},
journal={arXiv preprint arXiv:2403.17915},
year={2024}
}